Personalization Engine Setup: Include/Exclude Pages
Contents
When Personalization Engine detects a new URL on your site that it has not seen before, it will automatically spider that URL. The spider does not "crawl" through pages automatically following links. It will hit new URLs once. You can designate which URL structures the spider hits with include and exclude rules.
Including Content
Be careful with the syntax for Include URLs, especially ending in/. For example /http:\/\/www\.mydomain\.com\/[0-9-]\// would expect only ONE digit (or -) followed immediately by a /. So if your URL was http://www.mydomain.com/2013/0501/article.com then it would not be included in spidering.
A better option would be:
/http:\/\/www\.mydomain\.com\/[0-9-]+/
Excluding Content
When tracking user clicks or spidering content for a data feed, you may want to exclude some areas of your website. (For example, blogs or user response areas.)
Using the Recommendation Settings Page, you can instruct the spider to include/exclude specific content. Enter a specific URL or URL structure on each new line to instruct the spider what is okay to use and what is not.

Pageviews and tags are still tracked at the user profile-level for purposes of user session and interest tracking in the Personalization Engine domain. Content item pageview count will not be incremented if the content item does not pass spider rules. Exclude rules will also affect whether the page is spidered or not.
Paste the base literal URL into the Exclude field. For example:
URLs that are longer than 512 characters will be automatically excluded.
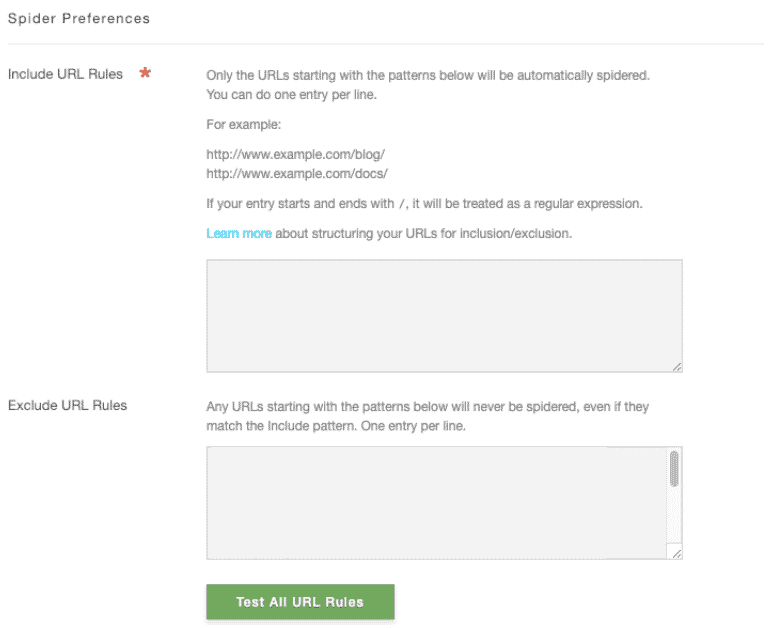
When excluding URLs, starting and ending a line with
Example:
Say you wanted to exclude the following URL type from spidering (an example WordPress page URL).
Pageviews and tags are still tracked at the user profile-level for purposes of user session and interest tracking in the Personalization Engine domain. Content item pageview count will not be incremented if the content item does not pass spider rules. Exclude rules will also affect whether the page is spidered or not.
Paste the base literal URL into the Exclude field. For example:
http://www.thedomainnottospider.com/notthiseither/
Otherwise, see Creating Expressions below.URLs that are longer than 512 characters will be automatically excluded.
When excluding URLs, starting and ending a line with
/ instructs the spider to treat the URL as a "regular expression" or "regex" for short. This means the spider will attempt to match the structure of the URL instead of taking it literally. http://www.mywebsite.com/2012/09/page/8Simply adding that URL to the "Exclude" area in the settings page would only block that specific address. This is a problem because we want to block all URLs that look like this. Luckily, most CMS use a standard structure for creating URLs. This example, WordPress, is no exception. When we look closely at the URL, it's easy to see the syntax in use:
http://www.mywebsite.com/YEAR/MONTH/page/DAYWe know that YEAR, MONTH and DAY will always be numerals. So we can put this into the start of an expression:
http://www.mywebsite.com/[0-9][0-9][0-9][0-9]/[0-9][0-9]/page/There are four
[0-9] for the year and two for the month. Note, we've left off the DAY's [0-9] because we know anything with the subdirectory /page/ should be excluded, thus making the DAY excessively specific. We're almost done, but first, we need to apply a little more detail so the spider fully understands its instructions. The next and final steps require a small bit of programming knowledge that we'll explain below.
Creating Expressions
1. To create a non-literal URL expression, you'll need to reference the chart below to set character ranges. See the Regular Expression Syntax Guide. 2. Next, we'll wrap the entire line with two characters, telling the spider we've created an expression and to not take the URL literally./http://www.mywebsite.com/[0-9][0-9][0-9][0-9]/[0-9][0-9]/page/// and .characters inherently part of the URL. To do this, we'll perform an escape on those other / and . characters.
In programming, an escape is performed by using a \ before the character we do not want confused. Note, this is the backslash, not the forward slash used in URLs.
This creates a pattern where each // and .. are preceded by a \, in turn looking like \/\/ or \.
Note: We do not do this for the / we added at the start and end of the line in the earlier step.
For example, let's take a look at the finished regex below:
/http:\/\/www\.mywebsite\.com\/[0-9][0-9][0-9][0-9]\/[0-9][0-9]\/page\//http://www.mywebsite.com/2011/09/page/8.
Regular Expression Syntax Guide
For further examples and explanations, we suggest visiting Mozilla's Developer Network regex page.| Character/Class | Description | Example |
|---|---|---|
\ |
Used to "escape" characters that have dual meanings: [/^$.|?*+(){} |
http:\/\/www.mywebsite.com\/subdirectory http:\/\/www.mywebsite.com\/subdirectory (escapes the / used in URLs) |
/ |
When used at the start and end of a URL, instructs spider to treat the example as an expression, not a literal URL. | /http:\/\/www.mywebsite.com\/[0-9]/ /http:\/\/www.mywebsite.com\/[0-9]/ |
For easier comprehension, the following examples do not include the above syntax. Note that escapes for.and /must be used when including and excluding regex URLs. |
||
[a-zA-Z] |
Character class: Any combination of upper- and lower-case letters, use a-z or A-Z for case sensitive situations |
http://www.mydomain.com/[a-zA-Z] looks for any subdirectory with solely letters without case sensitivity |
[0-9] |
Character class: Any combination of numeric characters 0-9 | http://www.mydomain.com/[0-9] looks for any subdirectory with solely numbers |
[a-zA-Z0-9] |
Character class: Any combination of alphanumeric characters upper- and/or lower-case | http://www.mydomain.com/[a-zA-Z0-9] looks for any subdirectory with any combination of numbers and/or upper- and lower-case letters |
{n} |
Where n >=1, repeats the previous item that number of times |
http://www.mydomain.com/[0-9]{4}/page looks for a subdirectory any four digits 0-9 with another subdirectory named "page", i.e. /4567/page |
. |
Match any single character (almost a wildcard, with a few exceptions) | http://www.mydomain.com/./page looks for any one-character subdirectory with another subdirectory named "page", i.e. /t/page |
* |
Repeats previous item | http://www.mydomain.com/.*/page any subdirectory with another subdirectory named "page", i.e. /subdirectory_name/page |
/b |
Matches a word boundary, defined by a non-word character. Word characters include [a-zA-Z0-9_] |
Excluding http://www.mydomain.com/page/b allows http://www.mywebsite.com/page/page2 but not http://www.mywebsite.com/page?=123 |
x(?!y) |
Matches x only if x is not followed by y. |
Excluding http://www.mydomain.com/[0-9][0-9](?!\/) allows http://www.mywebsite.com/12/page but not http://www.mywebsite.com/12 |
WordPress Posts Only
Example: If you want to include only WordPress posts in your Concierge feed, you could use the following expressions in the Allow/Exclude areas of the Recommendation Settings Page.
Please note, these expressions are based on a WordPress' Permalink structure. Use of custom structures may require modification of these examples.
Allow:
http://www.mywebsite.com//http:\/\/www\.mywebsite\.com\/[a-zA-Z]/ /http:\/\/www\.mywebsite\.com\/[0-9]{4}\/[0-9][0-9]\/[a-zA-Z]\// /http:\/\/www\.mywebsite\.com\/[0-9]{4}\/[0-9][0-9]\/.*\// /http:\/\/www\.mywebsite\.com\/[0-9]{4}\/[0-9][0-9]\b(?!\/)/ /http:\/\/www\.mywebsite\.com\/[0-9]{4}\b(?!\/)/Examples
Exclude your homepage, but include all other URLs that start with that base URL. EXCLUDE:/^http:\/\/www\.mydomain\.com$/
INCLUDE: /^http:\/\/(www.)?mydomain.com\/.+/
Exclude a specific section of pages on your site, but include the base URL and other sections. In this example, a sample URL that would be excluded is http://www.mydomain/thissection/3586
EXCLUDE: /http:\/\/www\.mydomain\.com\/thisection\/[0-9][0-9][0-9][0-9]/
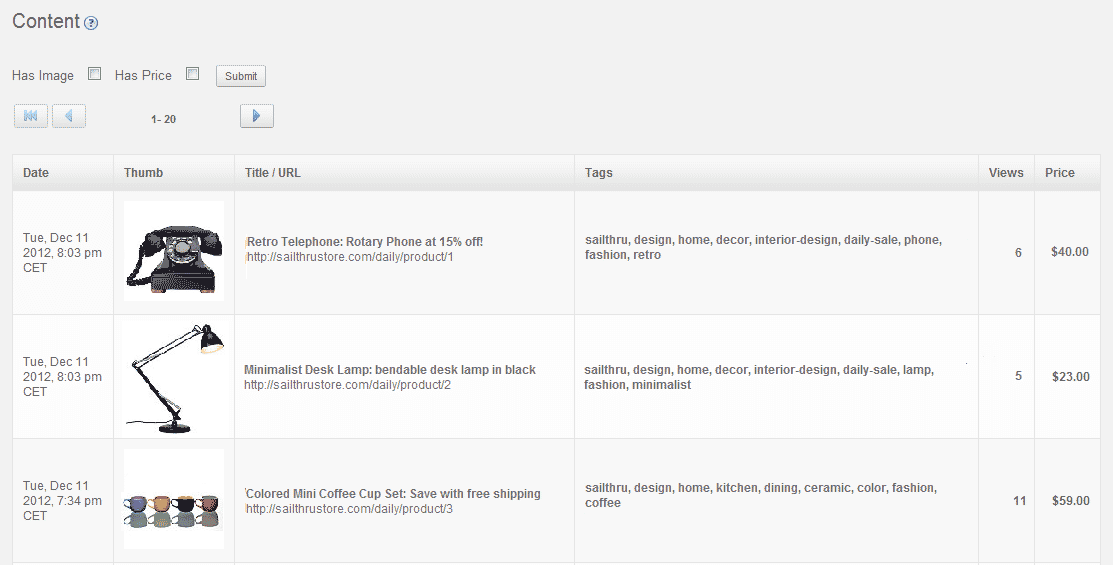
Spidered Content
To see the data that is being collected on your website, click to the Content tab > Spidered Content. You will see content listed under the following headers. See Personalization Engine Meta Tags for examples of how to set up these tags on your site.
- Date is the 'date' tag
- Thumb is the 'image.thumb' tag
- Title is the 'title' tag
- URL is the 'url' tag
- Tags is the 'Sailthru' or 'keyword' tag
- Views shows the number of page views by all users
- Price is obtained through purchase API